Databases
Please Log In for full access to the web site.
Note that this link will take you to an external site (https://shimmer.mit.edu) to authenticate, and then you will be redirected back to this page.
On the previous exercise you made a very simple Flask application. It was stateless meaning that it had no memory. When you provided two inputs to it, it responded a certain way, and it would continue to respond that same way forever. That might make sense in some situations, but in other situations we want to remember things for the purposes of data logging, or for the purposes of having stateful behavior. For this we need to remember things. And the proper way to do that is a database.
There are many different types of databases that exist, and while we do not mean to trivialize them in saying this, they all do pretty much the same thing, which is to provide a means to store and access information efficiently1. In this class we'll use SQLite2 which is a database management system. In order to interact with SQLite, we'll use SQL, which is a language used for managing databases. We will interact with SQLite and generate SQL commands in Python3 using the sqlite3 library which provides a convenient interface.
With SQLite, databases are files with the .db file extension. Within the database are tables, and within those tables are rows of data that we append to, extract from, and do whatever we want with. These files are automatically saved to the actual hard drive so if you have a Python script that messes with them in some way, and you run that Python script, after the script is finished, the changes made will live on into the future in that database, far beyond the lifespan of that Python file's runtime.
SQLite has a pretty easy-to-use Python interface once you get the basics of it. What's nice is that it is very modular so you can create databases and move/copy them as needed. Let's make a database. You'll want to start a Python process on your local computer. In general our order of operations will be
- import
sqlite3 - specify/create a database
- establish a connection to the database
- establish a cursor to the database (how we send it SQL commands)
- do stuff with the database (via the cursor)
- properly close connection to the database
In line with this approach, the snippet of code below will create a database called example.db and create a table within it. Create a file called db_experiment.py, place the code below in it, and run it:
import sqlite3
example_db = "example.db" # just come up with name of database
def create_database():
conn = sqlite3.connect(example_db) # connect to that database (will create if it doesn't already exist)
c = conn.cursor() # move cursor into database (allows us to execute commands)
c.execute('''CREATE TABLE test_table (user text,favorite_number int);''') # run a CREATE TABLE command
conn.commit() # commit commands (VERY IMPORTANT!!)
conn.close() # close connection to database
create_database() #call the function!
Now in your terminal locally on your computer run (in the same directory where your Python process was) ls. You should see a file in the list called example.db. What we've done is create a database that includes one table in it. We made this table by using a SQL command. Specifically, the command used was the following:
CREATE TABLE test_table (user text,favorite_number int);
which says: "create a table called 'test_table', and have it contain two columns, one which contains a text entry called 'user' and one which contains an integer entry called 'favorite_number'". (there are other data types of entries as well see here You may find the real data type to be useful for storing conventional floating point numbers in this lab!).
After execution and commitment, the structure of our database looks like the following:
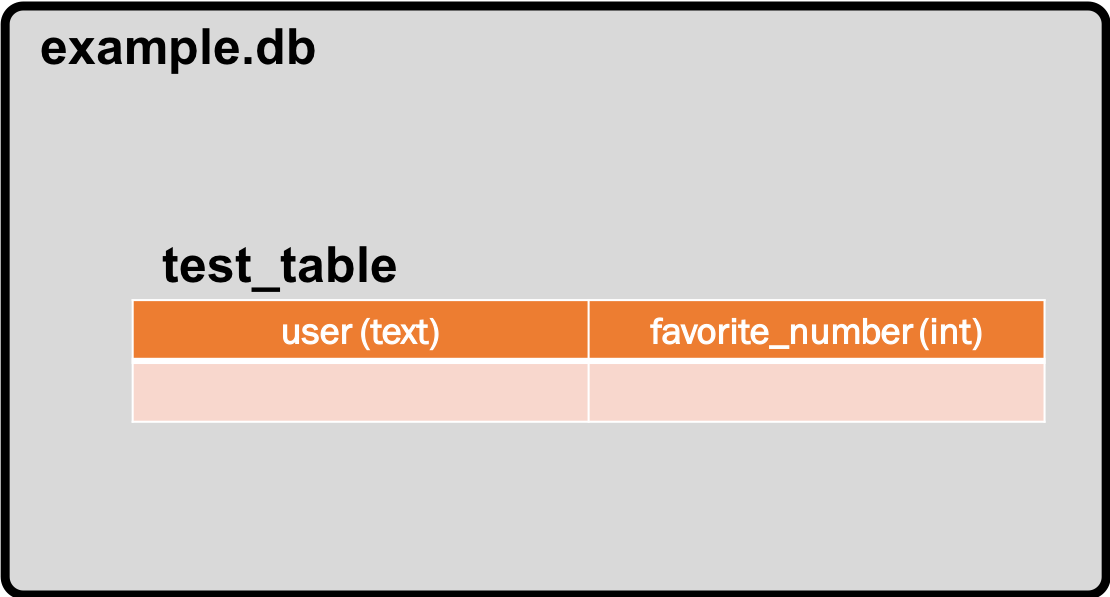
If you happen to run the same program again you'll get:
Traceback (most recent call last):
File "db_experiment.py", line 11, in <module>
create_database() #call the function!
File "db_experiment.py", line 7, in create_database
c.execute('''CREATE TABLE test_table (user text,favorite_number int);''') # run a CREATE TABLE command
sqlite3.OperationalError: table test_table already exists
And this is because when the function create_database runs the second time, it clashes with the fact that a table already exists in that database called test_table. You cannot have identically named tables in the same database. You can avoid this issue with the following command:
CREATE TABLE IF NOT EXISTS test_table (user text,favorite_number int);
If you're wondering where the syntax/grammar of the SQL command we used came from, it is standard SQL, which has numerous tutorials online like this one. SQL applies to a lot of the SQL family of databases out there3. Let's go and do more stuff with SQL in our database.
OK this database is pretty useless until we have some actual information in it. Let's add some stuff to the database then! Make another Python function called insert_into_database and add it to your db_experiment.py file. Copy-paste the lines of code below into that file, save it, and run it. Totally feel free to change the name and number too.
def insert_into_database():
conn = sqlite3.connect(example_db)
c = conn.cursor()
c.execute('''INSERT into test_table VALUES ('joe',5);''')
conn.commit()
conn.close()
insert_into_database() #call this function!
When it runs you'll see nothing happen probably...and that's good. In looking at the code, you should see a very similar structure to the first one, except the SQL command we run is the INSERT operation. In particular:
INSERT into test_table VALUES ('joe',5);
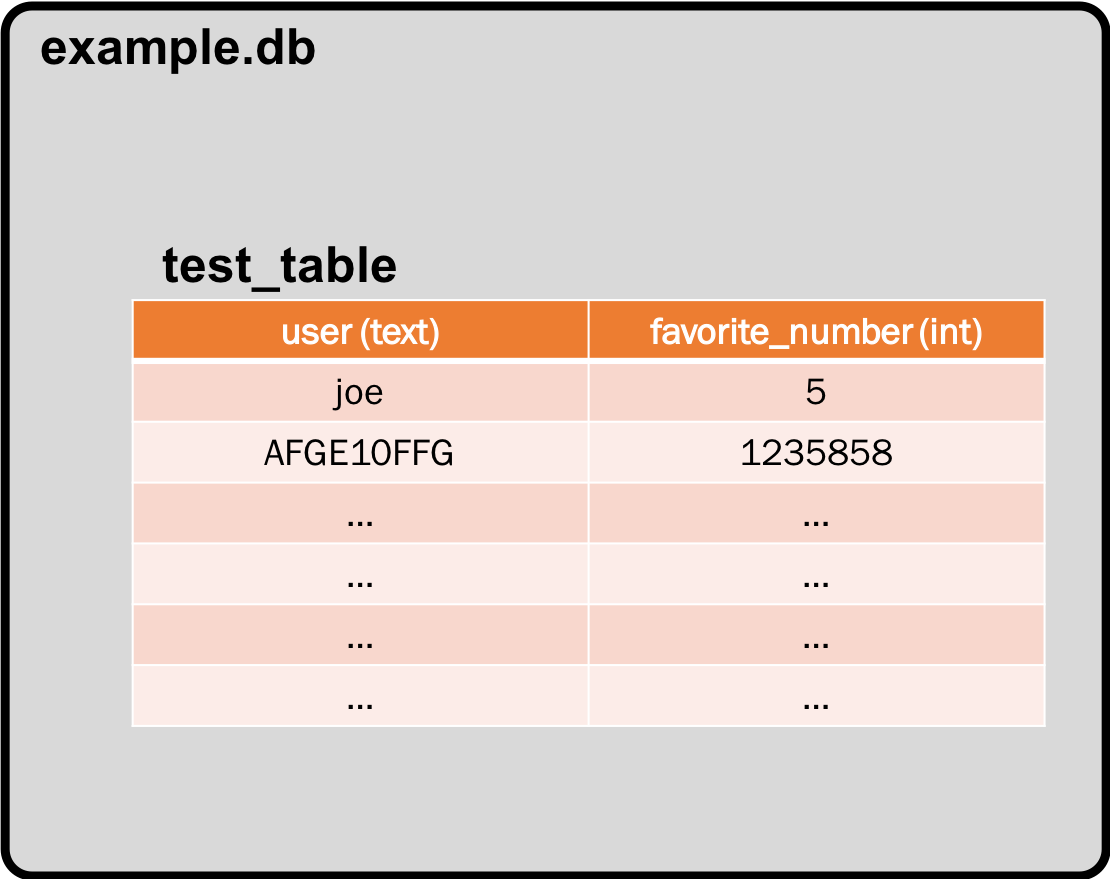
which says: "Insert into test_table, the values (in order with the table structure) of 'joe', then 5". This will result in the following new state to our database:

It would now be great to see what is in the database, and/or have the ability to extract information from it. For this we will need the SELECT operation. So, let's create another function called lookup_database with the structure shown below. Copy-paste the code below into the file we've been working in, comment out previous function calls, save it, and run it.
def lookup_database():
conn = sqlite3.connect(example_db)
c = conn.cursor()
things = c.execute('''SELECT * FROM test_table;''').fetchall()
for row in things:
print(row)
conn.commit()
conn.close()
lookup_database()#call it!
When you run it you should see (assuming you've only run the file once), and taking into account any name changes you might have made.
('joe', 5)
And this should make sense, since what we've done is run the SQL command:
SELECT * FROM test_table;
which says: "Select everything from test_table." (The * symbol is the wildcard, meaning 'everything') By default in SQLite, execution of a SELECT query will return a SQLite iterator, and you can use either the fetchone() or fetchall() methods to get the first returned value from the query or all returned values in a Python list, respectively, allowing us the ability to manipulate them as needed. Alternatively, we can use the iterator directly in a for loop, just like we do for the range() operator—if you just need to iterate over all the elements!
If you just want to see only the favorite number of each users in your database, instead of using * you could specify the columns you want to see such as:
SELECT favorite_number FROM test_table;
It is arguably good practice to avoid using * , but since we're just getting started we'll use it here. Just keep in mind in it is asking for everything and that may not be what you want or need. A safer way to ask for everything in our current table would be:
SELECT user, favorite_number FROM test_table;
When we inserted data into our database above, we had a pre-made (hard-coded) Python string that we used for our SQL command. In particular we did c.execute('''INSERT into test_table VALUES ('joe',5);''') which runs the SQL command INSERT into test_table VALUES ('joe',5);. What if we'd instead had some values we generated programatically that we wanted to be inserted into the database? For example, if we had a Python variable user and another variable favorite_of_user. How can we incorporate them into the SQL string we need to generate?
Well as we know in Python, we could create a string from other datatypes by casting and some concatenation action. For example we could do this (the old-school way):
''' to denote our strings though you could also use """ or likely even just " for what we're doing. Remember tripled-quoted strings allow us to specify multi-line stringssql_command = '''INSERT into test_table VALUES ('%s',%d);''' %(user,favorite_of_user)
c.execute(sql_command)
or if we did it the newer Python way, we could do it this way:
sql_command = '''INSERT into test_table VALUES ('{}',{});'''.format(user,favorite_of_user)
c.execute(sql_command)
or if we did it the even newer Python way with f-strings, we could do it like this:
sql_command = f'''INSERT into test_table VALUES ('{user}',{favorite_of_user});'''
c.execute(sql_command)
While not apparent nor a threat when running these databases on a local machine, this approach to building SQL commands can be a huge security flaw when our database is living on a server and the Python variables we're using to construct our SQL command are coming from user-specified values from GET or POST values. If a visitor to your site finds a way to manipulate the user variable to itself be a SQL command they can cause bad things to happen such as damage or destruction of your database. This is bad and is known as a SQL-Injection Attack and is the technical angle behind the comic below. Now you can say, "I get it."
In order to protect ourselves against this, inputs coming from "the outside" (anything you do not have complete control over such as user-specified inputs) should be sanitized and this can be done using the sqlite3 functionality shown below where insertion points of outside values are demarcated by question marks, and a following tuple provides the values to be inserted (in order). The SQLite Python library checks these values to make sure nothing SQL-like is in them, thus preventing injection:
c.execute('''INSERT into test_table VALUES (?,?);''',(user,favorite_of_user))
You can use SQL command syntax for all SQL queries we need to generate (creation of tables, selection of rows, etc...)
execute is a tuple, so if you have only one value to insert, you still need to make sure your tuple is of the form (value,) (yes that is a trailing comma there), otherwise you'll get an error. Please pay attention for this! I've wasted hours on this before and it is the least satisfying of bugs to figure out. You do not feel better after figuring this one out.
OK, I'm getting restless. Let's insert some more things into our database. Make a fourth Python function called, lotsa_inserts, copy-paste the code below into it, and run it. What this script does is create 100,000 random usernames and favorite numbers and inserts them one-after-the-other into the database:
#maybe put imports at top like one should do:
import random
import string
def lotsa_inserts():
conn = sqlite3.connect(example_db)
c = conn.cursor()
for x in range(100000):
number = random.randint(0,1000000) # generate random number from 0 to 1000000
user = ''.join(random.choice(string.ascii_letters + string.digits) for i in range(10)) # make random user name
c.execute('''INSERT into test_table VALUES (?,?);''',(user,number))
conn.commit()
conn.close()
lotsa_inserts() #Call this function!
If you now go back and rerun lookup_database, you'll get waaay more things that print because there are now waaay more entries in this database.
What if we wanted to return the user/favorite number pair with the largest favorite number in the database? One solution would be to build on the script we had, and get the entire database in a Python list, and then write some Python script for us to return the max. This can be ok for small databases, but as your database grows, having Python sort 500,000 entries or something can start to get pretty slow, and this is where more refined SELECTs and sortings can be done on the database side.4
The first thing we can do is modify our SQL query with a sort command, ORDER BY. In order to return the entire database in ascending order based on the value of favorite_number you'd run the following command:
SELECT * FROM test_table ORDER BY favorite_number ASC;
If you modify your lookup_database to have that command instead of the one we originally had in place, when you run it, you'll now see the entries in the database fly by in ascending order. If we want in descending order we could do this SQL command (try it to watch the values fly by in descending order)
SELECT * FROM test_table ORDER BY favorite_number DESC;
So far we've been running a query, generating a Python list from that query and then printing them all. If we wanted to print just the top entry, we could instead of a for loop, just do print(things[0]), but even then this can be slow because we're generating a really large Python list for no real reason other than it is in Python and that makes people feel safe. If we instead use the fetchone() method on an ordered response, we can get just a single value, and this can have significant speedup benefits. Consider the code below (which you could implement in a separate file if you'd like, so long as you keep the same directory so example.db is still accessible directly). If you run it on your currently existing database you should see a speedup of approximately three-fold between the two approaches. Please make sure you understand and appreciate why this is.
import sqlite3
import time
example_db = "example.db" #make sure this is run in the same directory as your other file.
conn = sqlite3.connect(example_db)
c = conn.cursor()
start = time.time()
things = c.execute('''SELECT * FROM test_table ORDER BY favorite_number DESC;''').fetchall()
print(things[0])
print(time.time()-start)
start = time.time()
thing = c.execute('''SELECT * FROM test_table ORDER BY favorite_number DESC;''').fetchone()
print(thing)
print(time.time()-start)
conn.commit()
conn.close()
You can also refine what is returned (and gain efficiency benefits) within the SQL query itself. For example the following SQL command is identical to the other two above, but limits what is done using SQL rather than the sqlite3 interface (and will give a speedup of about 20% or so on my machine with our current database as compared to our fast one above).
SELECT * FROM test_table ORDER BY favorite_number DESC LIMIT 1;
More details on the syntax of ORDER BY can be found here.
We can add further or alternative sorting mechanisms using the WHERE keyword. For example, if we wanted a list of users that had favorite numbers only between 1132 and 1185 (to identify weird people since only weird people have favorite numbers in that range, amirite?) we could do the following SQL command (try this out with the lookup_database function, and you should see a much smaller portion of your database print out)
SELECT * FROM test_table WHERE favorite_number BETWEEN 1132 AND 1185;
This command says, select all full rows in test_table where favorite_number is between 1132 and 1185.
We can nest our specifications as needed as well. The operation above will return a Python list of the entries that meet that condition, but what if we want that in order? We could do this by appending the ORDER BY operator from earlier, like below:
SELECT * FROM test_table WHERE favorite_number BETWEEN 1132 AND 1185 ORDER BY favorite_number DESC;
More details on syntax of WHERE can be found here.
Another really useful type which we can use with our databases are timestamps. SQLite sort of has undocumented support for timestamps, but when we use SQLite in conjunction with Python and its datetime library, we're able to remember and pull elements from arrays based on times (possibly of when that row was inserted or when that row was modified). We'll do that using a new type of entry, the timestamp. Consider the following code which creates a new database time_example.db, with a single table in it called dated_table that has three entries in it: a text field called "user", an int field called "favorite_number", and a timestamp field called "timing".
import sqlite3
import datetime
example_db = "time_example.db" # just come up with name of database
conn = sqlite3.connect(example_db) # connect to that database (will create if it doesn't already exist)
c = conn.cursor() # move cursor into database (allows us to execute commands)
c.execute('''CREATE TABLE IF NOT EXISTS dated_table (user text,favorite_number int, timing timestamp);''') # run a CREATE TABLE command
conn.commit() # commit commands
conn.close() # close connection to database
What is the SQL query in the above code snippet?
We'll use this new database like the old one, but instead here, we'll time-stamp entries as they are made using the datetime library, which is documented here.
We'd now like to populate that database with a few (5) fictitious users and their favorite numbers. We'll space when we enter these into the database by two seconds.
import sqlite3
import datetime
import string
import random
import time
example_db = "time_example.db" # name of database from above
conn = sqlite3.connect(example_db) # connect to that database
c = conn.cursor() # move cursor into database (allows us to execute commands)
for x in range(5):
number = random.randint(0,1000000) # generate random number from 0 to 1000000
user = ''.join(random.choice(string.ascii_letters + string.digits) for i in range(10)) # make random user name
c.execute('''INSERT into dated_table VALUES (?,?,?);''',(user,number,datetime.datetime.now())) #with time
print("inserting {}".format(user)) #notification message
time.sleep(2) #pause for 2 seconds before next insert
conn.commit() # commit commands
conn.close() # close connection to database
What is the SQL query in the above code snippet?
Just like the database before, we could then go and access and pull things out as needed:
import sqlite3
import datetime
example_db = "time_example.db" # name of database from above
conn = sqlite3.connect(example_db) # connect to that database
c = conn.cursor() # move cursor into database (allows us to execute commands)
things = c.execute('''SELECT * FROM dated_table;''').fetchall()
for x in things:
print(x)
conn.commit() # commit commands
conn.close() # close connection to database
But where this gets cool is we can start to sort off of timestamps. Below we create a datetime object that expresses "15 minutes ago" and then use that in combination with our SELECT query to get items from the last 15 minutes.
import sqlite3
import datetime
example_db = "time_example.db" # name of database from above
conn = sqlite3.connect(example_db) # connect to that database
c = conn.cursor() # move cursor into database (allows us to execute commands)
fifteen_minutes_ago = datetime.datetime.now()- datetime.timedelta(minutes = 15) # create time for fifteen minutes ago!
things = c.execute('''SELECT * FROM dated_table WHERE timing > ? ORDER BY timing DESC;''',(fifteen_minutes_ago,)).fetchall()
for x in things:
print(x)
conn.commit() # commit commands
conn.close() # close connection to database
What is the SQL query in the above code snippet?
Further documentation on the Python datetime library can be found here.
Ok everything we've done so far can totally be done in the context of a Flask application. A very, very simple deviation on the Flask application from the previous exercise could be that it logs all of the products it ever calculates and then will return not just the current result, but rather the amount previous results. So something like: http://ERROR/efi_test/math?x=6&y=11&amount=4 wouldn't just yield 66.0 but rather
6.0 times 14.0 is 84.0! 6.0 times 14.0 is 84.0! 6.0 times 14.0 is 84.0! 6.0 times 14.0 is 84.0! 6.0 times 8.0 is 48.0! 6.0 times 11.0 is 66.0! 5.0 times 11.0 is 55.0! 5.0 times 11.0 is 55.0! 5.0 times 11.0 is 55.0! 5.0 times 11.0 is 55.0!
A behavior like that could be implemented with the following:
from flask import Flask, request
import sqlite3
app = Flask(__name__)
MATH_DB = "/home/jodalyst/efi_test/math_log.db"
@app.route("/")
def hello():
return "hello from jodalyst"
@app.route("/math", methods=['GET'])
def math_function():
args = request.args
try:
x = float(args['x'])
y = float(args['y'])
amount = int(args['amount'])
result = x*y
conn = sqlite3.connect(MATH_DB) # connect to that database (will create if it doesn't already exist)
c = conn.cursor() # move cursor into database (allows us to execute commands)
c.execute('''CREATE TABLE IF NOT EXISTS math_table (x real,y real, result real);''') #jodalyst test
c.execute('''INSERT into math_table VALUES (?,?,?);''', (x,y,result))
things = c.execute('''SELECT * FROM math_table ORDER BY rowid DESC LIMIT ?;''',(amount,)).fetchall()
#rowid is an implicit 64 bit ordered row counter column that exists in all sqlite tables by default.
# you can use it to access most recents
conn.commit() # commit commands
conn.close() # close connection to database
outs = ""
for t in things:
outs += f"{t[0]} times {t[1]} is {t[2]}!\n"
return outs
except Exception as e:
return str(e)
if __name__ == "__main__":
app.run(host='0.0.0.0')
Couple things of note in this example code:
You can create databases on the server automatically, but also add the caveat to only do so if the database doesn't already exist. This prevents a crash when you try to make a new database that already is there. The syntax we use above tries to create the database if it doesn't exist, and then adds a new entry to the database and returns what is currently in it.
All tables made in sqlite will have an implicit auto-indexing counting row called "rowid". This can be very useful when sorting on oldest or newest data. More info here.
Ok what we want for a deliverable for this exercise is very similar to the code above, except the number of previous results it provides should be based on timestamps rather than the raw index count.
We want something like: http://ERROR/efi_test/math_timed?x=6&y=11&history=3 where x and y are the usual suspects and history takes in an argument and lists out the previous inputs that were within history seconds in the past.
So starting from a pause of a long time: http://ERROR/efi_test/math_timed?x=6&y=11&history=2 should yield 6.0 times 11.0 is 66.0!.
Then if one second later you do:http://ERROR/efi_test/math_timed?x=2&y=2&history=2 you should get 2.0 times 2.0 is 4.0! 6.0 times 11.0 is 66.0!.
Then if 1.1 seconds later you did http://ERROR/efi_test/math_timed?x=3&y=2&history=2 you should get 3.0 times 2.0 is 6.0! 2.0 times 2.0 is 4.0!. (since the original submission was greater than 2 seconds ago).
When you think you have it working, run the checker below.
